As of 19th of Jan 2016, it means that the scripts here that use the geom_smooth() don't work. I will repair them all but it'll take a few days. Thanks to the commentors for sorting this out.
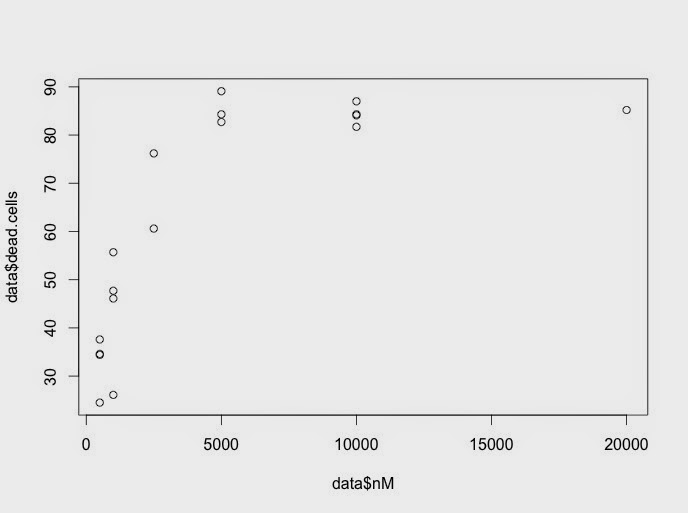
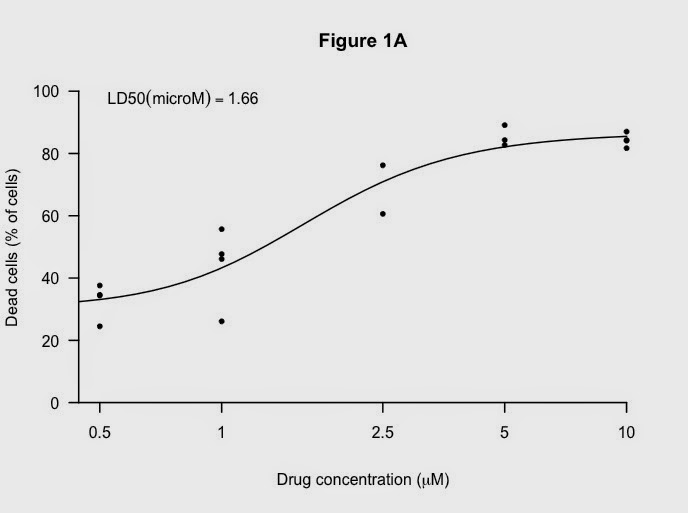
As mentioned previously, we do a lot of drug testing in our laboratory.
Here is the same data plotted with ggplot.
The experimental set up, done by a student in the lab, is as follows:
- using some cells and add various concentrations of a novel drug
- leave for 48 hours
- then measure how many cells are dead
- the experiment was done four times with the doses improved each time
Here is the graph and calculated LD50 - a measure of how good the drug is:


Here is the script:
# START of SCRIPT
library(ggplot2)
### this is the data ###
# data from four experiments
conc <- c(5.00E-07, 1.00E-06, 1.00E-05,
5.00E-07, 1.00E-06, 5.00E-06, 1.00E-05, 2.00E-05,
5.00E-07, 1.00E-06, 2.50E-06, 5.00E-06, 1.00E-05,
5.00E-07, 1.00E-06, 2.50E-06, 5.00E-06, 1.00E-05)
dead.cells <- c(34.6, 47.7, 81.7,
37.6, 55.7, 89.1, 84.3, 85.2,
34.4, 46.1, 76.2, 84.3, 84.1,
24.5, 26.1, 60.6, 82.7, 87)
# transform the data to make it postive and put into a data frame for fitting
data <- as.data.frame(conc) # create the data frame
data$dead.cells <- dead.cells
data$nM <- data$conc * 1000000000
data$log.nM <- log10(data$nM)
### fit the data ###
# make sure logconc remains positive, otherwise multiply to keep positive values
# (such as in this example where the iconc is multiplied by 1000
fit <- nls(dead.cells ~ bot+(top-bot)/(1+(log.nM/LD50)^slope),
data = data,
start=list(bot=20, top=95, LD50=3, slope=-12))
m <- coef(fit)
val <- format((10^m[3]),dig=4)
### ggplot the results ###
p <- ggplot(data=data, # specify the data frame with data
aes(x=nM, y=dead.cells)) + # specify x and y
geom_point() + # make a scatter plot
scale_x_log10(breaks = c(500, 1000, 2500, 5000, 10000, 20000))+
xlab("Drug concentration (nM)") + # label x-axis
ylab("Dead cells (% of cells)") + # label y-axis
ggtitle("Drug Dose Response and LD50") + # add a title
theme_bw() + # a simple theme
expand_limits(y=c(20,100)) # customise the y-axis
# Add the line to graph using methods.args (New: Jan 2016)
p <- p + geom_smooth(method = "nls",
method.args = list(formula = y ~ bot+(top-bot)/(1+( x / LD50)^slope),
start=list(bot=20, top=95, LD50=3, slope=-12)),
se = FALSE)
# Add the text with the LD50 to the graph.
p <- p+ annotate(geom="text", x=7000, y= 60, label="LD50(nM): ", color="red") +
annotate(geom="text", x=9800, y= 60, label=val, color="red")
p # show the plot
#END OF SCRIPT